( * Kafka Definitive Guide - Chapter 8. Exactly-Once Semantics 내용에 기타 Reference 자료를 추가해 정리해놓은 글입니다. )
Idempotent Producer
어떤 연산이 있을 때 몇번을 재 실행해도 그 결과 State가 동일하다면 Idempotent 하다고 한다.
ex-1) UPDATE t SET x=18 where y=5 는 Idempotent 하다.
ex-2) UPDATE t SET x=x+1 where y=5 는 Idempotent 하지 않다.
Producing 과정에서 Duplicated Producing은 Leader가 Message를 받고 성공적으로 Replication을 수행한 후 Producer에게 성공 메시지를 보내는 찰나에 Leader가 Crash나는 상황에서 발생한다. Producer는 성공 메시지를 기다리다 timeout 되면 실패로 여기서 re-write를 하게 되고, Duplicated Produce가 발생한다.
How Does the Idempotent Producer Work?
https://medium.com/@shesh.soft/kafka-idempotent-producer-and-consumer-25c52402ceb9
Producer가 “enable.idempotence=true” 로 Session을 생성하면 Producer는 Broker에 메시지를 보낼 때 마다
{ Unique Producer-ID, Sequence Number} 값을 함께 보낸다. Broker는 각 Producer마다 Unique한 { Unique Producer-ID, Sequence Number} 값을 가진 메시지만 ACK하고 나머지는 Deny하는 방법으로 Idempotent Producer를 구현한다. Sequence Number는 언제나 1씩 증가하는 값이며 이 값의 대소 비교를 이용해 메시지의 Unique함을 보장할 수 있다.
Producer restart
Producer에 failure가 생겨서 Kubernetes에 의해 재시작 되었다고 하자. 이때 Producer는 Kafka Broker와 연결된 후 새로운 Producer ID를 부여 받는다. 즉 재시작된 Producer는 이전과는 완전히 다른 Idempotent Context를 가진다. 이 상태에서 이전에 Produce 했던 메시지를 다시 생성하면 Kafka Broker는 전혀 존재하는 메시지라고 여길 수 없다.
Broker failure
Kafka Broker는 Sequence Number Window를 파티션 Leader의 In-Memory Buffer에서 유지한다. 또한 모든 ISR 역시 이 In-Memory Sequence Number 를 유지한다.
따라서 갑자기 Broker가 Crash나서 다른 Replica가 Leader가 되어도 Sequence Number Window를 이용해 Idempotent 기능을 유지할 수 있다.
Limitations of the Idempotent Producer
Idempotent Producing는 오직 producer.send() 내부에서 retry를 할 때 발생하는 Duplication만 방지할 수 있다.
즉 Producing에 성공해서 Leader가 Producer에게 성공 메시지를 보내는 찰나에 Leader가 Crash나는 상황에서 발생하는 Duplication을 방지하는 수단일 뿐이다.
Producer가 Leader로 부터 성공메시지를 받았다고 생각해보자. 이제 Producer는 성공했다는 정보를 User에게 응답해 주거나 DB에 반영해야 한다. 이 찰나에 Producer가 Crash나면 Message Write는 성공했지만 User에게 성공 메시지를 돌려 주지 않았거나 DB에는 반영이 돼 있지 않기 때문에 User가 다시 재구매를 한다는 등의 Duplication이 발생할 수 있다.
How Do I Use the Kafka Idempotent Producer?
acks=all을 이미 사용하고 있는 상황이라면 Idempotent를 쓴다고 Performance가 저하되는 일은 없다.
Transaction
- Batch Processing vs Stream Processing : https://www.upsolver.com/blog/batch-stream-a-cheat-sheet
- Transactions in Apache Kafka ( Confluent.io ) : https://www.confluent.io/blog/transactions-apache-kafka/
Kafka의 Transaction은 source topic으로 부터 “consume - process - produce” 작업을 한 후 dest-topic에 저장할 때 Duplication 없이 dest-topic에 한번만 저장하는 것을 보장한다. ( *중간에 Processing 과정은 여러번 수행될 수 있다! 최종적으로 dest-topic에 저장되는 것이 중복/누락 없도록 보장하는 거다. )

What Problems Do Transactions Solve?
Kafka의 Transaction의 목표는 Source Topic의 메시지를 하나를 꺼내왔을 때 Dest Topic에 정확히 하나를 생성하는 것이다.
우선 위에서 설명한 “consume - process - produce” 작업을 다음과 같은 3개의 작업으로 나누어 볼 수 있다.
1. Consumer가 source-topic에서 Message을 가져오고 Processing한다.( 이때 Consumer의 offset commit을 update하지 않는다. )
2. Producer가 해당 메시지를 이용해 새로운 메시지를 생성한다.
3. Consumer의 offset commit을 update한다.
while (true) {
ProducerRecord<String, String> record = processing(consumer.poll()); // 1
producer.send(record); // 2
consumer.commitSync(); // 3
};
이런 상황에서는 우선 절대 Data Loss가 발생하지는 않는다. 3번이 성공할 때 까지 Consumer의 offset commit이 update되지 않아 계속 Crash가 나도 나중에 계속 retry를 할 수 있기 때문이다.
문제는 Duplication인데 이 상황에서 발생할 수 있는 Duplication에 대해 살펴보자.
- Duplication by Crash
2번 과정에서 Dest-Topic에 새 메시지 생성을 완료했다고 하자. 이때 3번 과정 ( offset commit을 update하는 과정 )을 수행하기 전에 Kafka Broker나 Client에서 문제가 생겼다고 해보자. 그럼 다시 1번과 2번을 수행하게 되고 2번 과정에 의해 Dest-Topic에 새 메시지를 생성해 중복 생성을 하게 된다.
이를 해결하기 위해 다음과 같은 방법을 사용한다.
1. Consumer가 source-topic에서 Message을 가져오고 Processing한다.( 이때 Consumer의 offset commit을 update하지 않는다. )
2. Producer가 해당 메시지를 이용해 “새로운 메시지를 생성하고 Consumer의 offset commit을 update하는 작업을” Atomic하게 수행한다. 이를 atomicProduceAndUpdateOffsetCommit함수라 하자. ( 이따 살펴볼 Atomic Multi Partition Writes를 이용해 Atomic하게 두 작업을 수행할 수 있다. )
while (true) {
ProducerRecord<String, String> record = processing(consumer.poll()); // 1
atomicProduceAndUpdateOffsetCommit(record); // 2
};
2번 작업이 Atomic하다면 이제 갑작스런 Crash에 의한 Duplication Write는 막을 수 있다. 그런데 또 한가지 문제가 있는데 바로 Zombie Instance이다.
- Zombie Instance에 의한 Duplication
만약 Application이 2번 작업을 수행하는 찰나에 Connection이 끊겼다고 생각해 보자. 그러면 새로운 Instance가 생성되어 1번, 2번 과정을 다시 수행했다. 이때 connection이 끊겼던 Instance가 다시 연결되면 다시 Produce작업을 수행하게 된다.
이런 상황에서는 atomicProduceAndUpdateOffsetCommit 함수가 확보했던 Atomic 성질이 사라지게 된다. atomicProduceAndUpdateOffsetCommit는 동시에 오직 하나의 Instance가 동작함을 가정했기 때문이다. 따라서 OPTIMISTIC_LOCK 과 비슷한 메커니즘이 필요하다.
How Do Transactions Guarantee Exactly-Once?
Kafka Transaction은 “atomic multi partition writes” 으로 Transaction을 구현한다.
Consumer Group은 Rebalance시 Consumer가 다시 어디서 부터 다시 읽어야 한다는 정보를 특정 Topic에다 기록한다. 그래서 Application이 Crash가 나도 Kafka Cluster에 기록된 Consumer offset commit을 참고해서 어디까지 consume했는지 알 수 있다.

이때 consumer가 offset commit을 기록하는게 아니라 이후에 Producer가 Atomic하게 Dest-Topic에 Produce를 하는 동시에 Consumer offset commit을 기록하게 하면 “consume - process - produce” 과정에서 exactly-once가 지켜진다. 이때 consumer의 offset commit을 기록하는 Topic을 __consumer_offsets 라 한다.

Zombie Fencing
또한 Zombie Producer를 방지하기 위해 transactional.id를 활용한다. Producer를 생성할 때 동일한 “transactional.id” 값을 넣으면 해당 항상 동일한 Producer ID를 할당받는다. 즉 Kafka는 Cluster에 transactional.id를 Producer ID로 맵핑하는 데이터를 저장하고 관리한다.
Producer ID는 producer.initTransactions() 함수 실행시 부여받는데, 이때 epoch값 역시 생성된다. epoch값은 이전에 생성된 zombie Producer를 구분하기 위한 값으로 initTransactions을 호출할 때 마다 증가한다. 따라서 가장 최근에 생성된 Producer가 producer.initTransactions를 호출할 때 epoch값을 증가시키고, 이때 Zombie Producer가 가진 old한 epoch값은 Producing을 할 때 Reject를 당한다.
epoch를 Lock개념으로 말하자면 OPTIMISTIC_LOCK 인데 가장 먼저 확보하는 사람이 획득하는게 아니라 가장 최후에 확보하는 사람이 획득할 수 있는 Lock이다.

Isolation Level
카프카가 Transactional Producer가 마지막으로 Produce한 메시지가 commit되면 LSO(Last Stable Offset)이 해당 메시지를 가리킨다. 만약 Transactional Producer가 Produce한 메시지가 아직 commit되지 않았다면 LSO offset은 아직 이전 Message를 가리키는 상태이다. Rollback시엔 LSO 이후에 쌓인 메시지를 모두 폐기한다.
이때 isolation.level=read_uncommitted 인 Consumer은 LSO이후의 메시지 까지 읽어들인다. ( default : read_uncommitted )

What Problems Aren’t Solved by Transactions?
앞서 이야기 했듯 Kafka의 Transaction은 단지 Source Topic 메시지를 이용해 중복/누락 없이 Dest-Topic이 저장 하는걸 보장할 뿐이다.
만약 중간에 있는 Processing작업 ( mail-send 작업, Database write)을 단 한번 하고 싶다면 다른 방법을 찾아봐야 한다.
Reading from a Kafka topic and writing to a database
- 동일한 RDBMS의 Transaction에서 Database에 Write하는 동시에 Kafka에도 Write를 한다. ( OutBox Pattern )
이때는 OutBox Pattern을 쓴다.
DB에 존재하는 메시지를 Exactly Once로 Kafka Queue에 집어 넣는 방법은 역시 Atomic Multi Partition Write로 구현할 수 있다.
OutBox테이블에는 Sequence 값과 함께 메시지를 저장한다. CDC Producer는 next-outbox-seq Topic으로부터 Seq값을 가져온 Seq에 해당하는 메시지를 DB로 부터 읽어 와 Atomic Multi Partition Write로 “dest-topic에 쓰는 동시에 next-outbox-seq의 Seq값을 +1로 Update” 연산을 수행한다.

- Kafka에서 읽어온 데이터를 Database에 Write 할때
이 경우는 Kafka에서 메시지를 Consume하는 동시에 Database에도 Write 해야 한다.
Kafka에선 Consumer가 Data Loss를 완벽히 방지하면서 동시에 Duplication 역시 막을수 있는 방법은 둘중 양자 택일을 해야한다.
따라서 Consumer는 Data Loss를 막는 방법으로 Processing을 먼저 수행한 후 offset commit을 update한다. 대신 Consumer가 여러번 Consumer을 해도 DB 에는 한번만 Write되게 (Idempotent하게) 쿼리를 짜야한다.

혹은 Database에서 Kafka의 offset commit을 관리하는 방법이 있다.
@Transactional
public void transactionalDBOffsetUpdate() {
long offset = kafkaTopicRepo.readOffset(partitionId);
consumer.seek(partition, offset);
ConsumerRecords<String, String> records = consumer.poll();
//...
userRepo.write(data);
long commitOffset = offset + records.count();
kafkaTopicRepo.writeOffset(partitionId, commitOffset);
}
Publish/subscribe pattern
Transactional Producer로 Consume/Produce가 아니라 Produce/Consume을 하면 어떻게 될까?
producer.beginTransaction();
producer.send(customizedRecord);
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis());
process(records); // Do processing
Map<TopicPartition, OffsetAndMetadata> offsets = consumerOffsets();
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());
producer.commitTransaction();
read committed라면 Producer가 현재 Transaction에 파티션에 추가한 건 Consumer가 읽을 순 없다. read_committed에서는 commit이 끝날 때 LSO( Last Stable Offset) 이 후의 메시지를 읽을 수 없기 때문이다.
하지만 Consumer가 여러번 Processing 하는 걸 막을 수는 없다. Consumer은 commit을 하기 전에 __consumer_offset 보다 큰 값의 offset들의 메시지를 읽고 Processing을 하는데 revert 되면 consumer는 다시 __consumer_offset 보다 큰 값의 offset들의 메시지를 읽어 processing 하게 된다.

Transactional IDs and Fencing
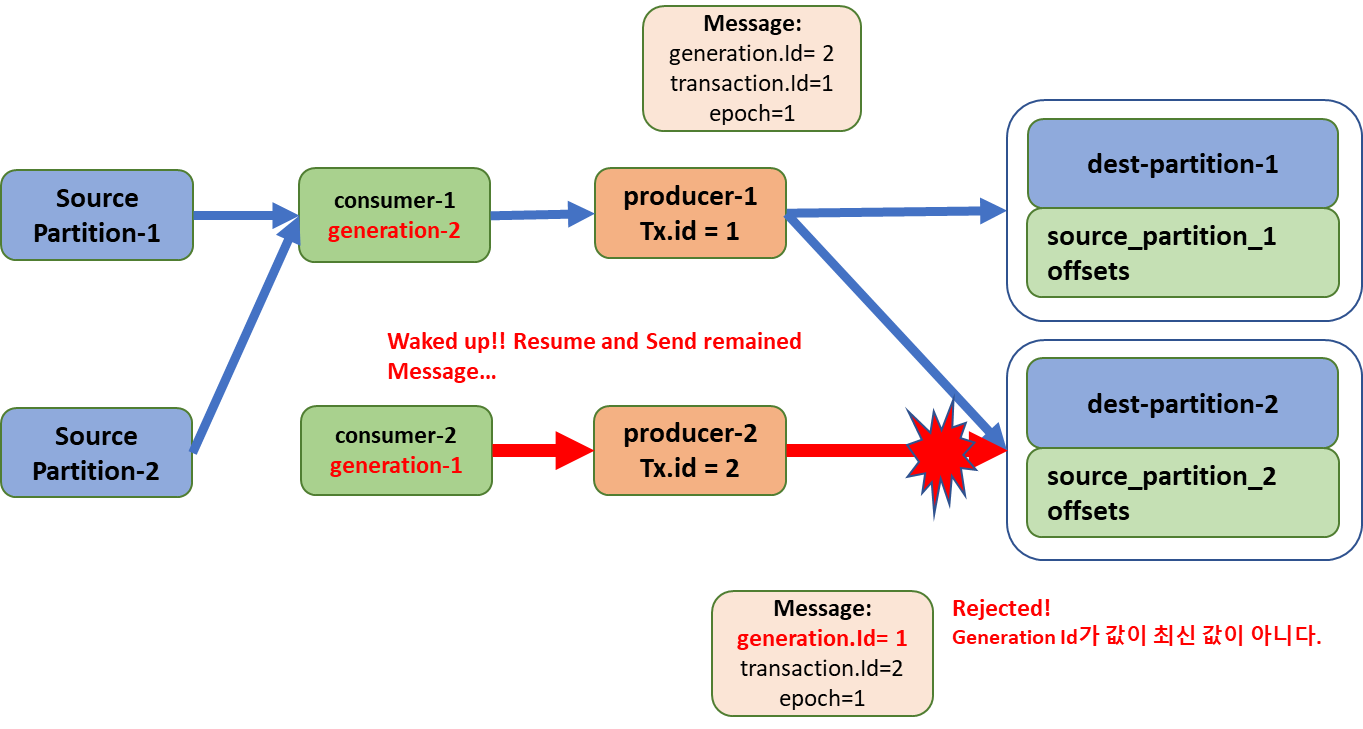
Kafka 2.5 버전 이전의 EOS Fencing 문제
2.5 버전 이전에는 위에서 살명한 대로 Transactional.Id 값이 같을 때 epoch값을 비교해 Zombie fencing을 진행했다. Transactional.Id가 다르다면 Transaction이 진행 중이어도 Write가 가능하다.
이런 방어 방법은 한가지 가정을 한 구현방법이었는데 바로 Consumer의 Input Paritition이 변하지 않게 유지된다는 가정이다. 하지만 실제로는 Rebalance로 인해 변동적인 Partition을 Input으로 사용하게 된다.
이때 어떤 문제가 발생하는지 살펴보자.
- 1. 2 개의 Instace가 작동중이다. 그러다 갑자기 Instance 2의 jvm이 Garbage Collecting을 너무 오래 해버려서 Partition Rebalance에 의해 Partition소유권을 잃어 버렸다. Partition 2의 소유권은 consumer-1로 넘어갔고 producer-1은 해당 메시지를 받아 Transactional Write를 한다.

- 2. 그러다 갑자기 consumer-2가 깨어났다. 이때 아직 Processing 중이던 메시지가 있었는데 Producer-2 마저 전송했다. 하지만 Kafka는 Transaction.id가 같아야만 Zombie fencing을 한다. 따라서 producer-2는 Write에 성공하고 EOS가 침해된다.

KIP-447 에서 고안한 방법
KIP-447에서는 Rebalance가 발생할 때 마다 Consumer Group이 새로운 epoch값을 가지게 설정했다.
Rebalance가 발생할 때 마다 Consumer Group이 Generation-Id 라는 epoch값을 매번 더 높은 값으로 갱신한다.
Producer가 Transactional Commit Request를 날릴 때 반드시 이 Generation-Id값을 포함시켜야 하는데 Kafka Broker는 old한 Generation-Id가 도착하면 바로 Zombie process라 판단한다. ( Rebalance는 Consumer Group 내에서 발생하므로 다른 Consumer Group은 그 Consumer Group에서 따로 Rebalance가 발생해야 epoch가 update된다.)
| TxnOffsetCommitRequest => TransactionalId GroupId ProducerId ProducerEpoch Offsets GenerationId TransactionalId => String GroupId => String ProducerId => int64 ProducerEpoch => int16 Offsets => Map<TopicPartition, CommittedOffset> GenerationId => int32, default -1 // NEW … |
How Transactions Work : Protocol
https://www.confluent.io/blog/transactions-apache-kafka/
https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit#
https://docs.google.com/document/d/11Jqy_GjUGtdXJK94XGsEIK7CP1SnQGdp2eF0wSw9ra8/edit#
https://www.waitingforcode.com/apache-kafka/isolation-level-apache-kafka-consumers/read
Kafka는모든 각 파티션 마다 Transaction Log를기록하기 위해 __transaction_state 라는 internal topic을 이용한다(즉 각 파티션 마다 __consumer_offsets, __transaction_state 두 개의 internal topic이 운영된다. https://github.com/a0x8o/kafka/blob/master/clients/src/main/java/org/apache/kafka/common/internals/Topic.java#L28 ). __transaction_state또한 Kafka Broker는 각 Producer들의 transaction coordinator로 지정되어 __transaction_state를 관리한다.
transaction state : https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/admin/TransactionState.java#L27
- TransactionState.java
public enum TransactionState {
ONGOING("Ongoing"),
PREPARE_ABORT("PrepareAbort"),
PREPARE_COMMIT("PrepareCommit"),
COMPLETE_ABORT("CompleteAbort"),
COMPLETE_COMMIT("CompleteCommit"),
EMPTY("Empty"),
PREPARE_EPOCH_FENCE("PrepareEpochFence"),
UNKNOWN("Unknown");
//..
}
이제 __transaction_state는 Transaction Log 라고 부르기로 하자. 이제부터 Transaction Log는 __transaction_state을 뜻한다.
- initTransaction()
producer.initTransaction()을 호출하면 InitProducerId Request를 Transaction Coordinator에게 보낸다.
Trasanction Coordinator는 그럼 다음을 수행한다.
- 1. trasnaction.id로 진행되는 transaction이 이미 Transaction Log에 아직 존재하지 않는다.
-> Transaction Log에 Transaction을 시작한다는 메시지로 {state: empty, transactional ID, bumped epoch (증가된 epoch)} 값을 집어 넣고 Response를 Producer에 반환해준다.
- 2. trasnaction.id로 진행되는 transaction이 이미 존재한다.
2.1 empty or on-going 상태이다 ( prepare-commit 상태가 아니다. ) : on-going 중인 Transaction을 abort 처리한다. Transaction을 abort처리가 완료 되기까지 initTransaction은 Block된다. abort 처리가 완료되면 1에서 처럼 Transaction Log에 시작 메시지를 집어 넣는다. 그 후 Response를 Producer에 반환해준다.
2.2 나머지는 prepare-commit 상태인 경우이다. commit이 될 때까지 기다린다. 그 후 1에서 처럼 Transaction Log에 시작 메시지를 집어 넣는다. 그 후 Response를 Producer에 반환해준다.

- beginTransaction()
이 함수가 호출 되었을 때는 Coordinator에게 아무런 Request를 보내지 않는다. 그냥 Producer local에만 Transaction이 시작되었다는 걸 표시하는 함수다.
- produce()
Producer가 Transaction 상태일 때 produce()함수가 호출되면 Producer는 produce의 Target Partition이 현재 Transaction에 연루되어 있다는 AddPartitionsToTxn Request를 Coordinator에게 보낸다. 아래 그림에서 보이듯 AddPartitionToTxnRequest Request에 의해 on-going으로 상태가 변경되며 추가로 AddPartitionsToTxn Request가 전송될 때 마다 Transaction Log에 새로운 Log가 추가된다.

- sendOffsetsToTransaction()
단지 consumer의 offset topic에 메시지를 추가한다는 것 말고는 produce()와 동일하다. offset-topic 역시 이번 Transaction에 연루되므로 Transaction-Log에 연루된 파티션으로 추가된다.
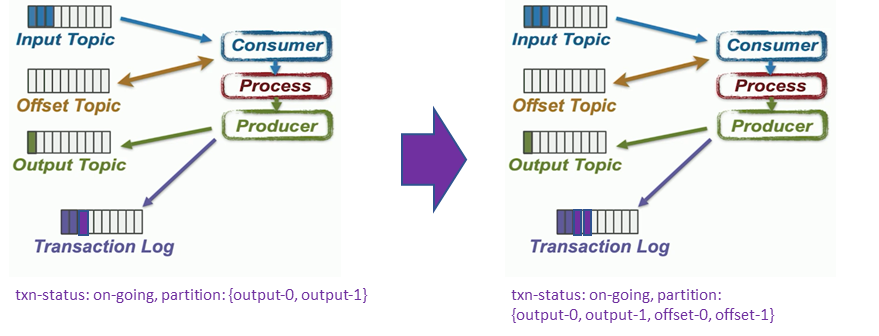
- commitTxn() : Synchronization 이전
commitTxn()함수는 Transaction Coordinator에 EndTxnRequest를 날린다. Transaction Coordinator는 CommitTxnRequest 을 받으면 prepare-commit 단계에 진입한다. 최종 commit은 연루된 모든 Partition Leader들 과의 Synchronization이 필요하다. Synchronization과정은 Chandy-Lamport snapshots 비슷한 방법을 사용한다.
http://composition.al/blog/2019/04/26/an-example-run-of-the-chandy-lamport-snapshot-algorithm/
Transaction Coordinator는 “Marker” 메시지 역할을 하는 WriteTxnMarkerRequest를 각 브로커들에게 날린다. ( 연루된 파티션들의 리더가 존재하는 브로커들)에 날린다. 이 메시지를 받은 브로커(혹은 파티션 리더)는 연루된 파티션에 commit Marker을 집어 넣는다. 이후 WriteTxnMarkerRequest에 대한 응답으로 WriteTxnMarkerResponse를 돌려준다.

- commitTxn() : Synchronization 이후
연루된 모든 Partition Leader들로 부터 WriteTxnMarkerResponse 응답을 받으면 commit 상태를 Transaction Log에 집어 넣는다.

How Transactions Work : Aborted Transaction
https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit#
https://www.waitingforcode.com/apache-kafka/isolation-level-apache-kafka-consumers/read
그렇다면 Abort된 Transaction은 Kafka 내부에서 어떻게 다룰까?
사실 Abort된 Transaction의 메시지라 하더라도 연루된 Partition에는 메시지가 그대로 들어가 있다. 또한 해당 메시지들은 Consumer에게 그대로 전달된다. 따라서 Aborted된 Transaction의 메시지인지 아닌지 Consumer 입자에서 판단해야 한다( Kafka Consumer 쪽의 프로토콜 처리 로직에서 알아서 처리해주기에 우리는 그걸 알아챌 수 없다. )
우선 Consumer가 isolation.level=READ_COMMITTED 로 FetchRequest를 날린 경우를 봐보자.
Kafka 브로커는 FetchRequest에 대한 응답으로 다음과 같은 Response를 돌려 준다.
( *FetchResponse는 여러 개의 MessageSet을 반환하는 데 MessageSet 역시 PID가 동일한 여러 개의 Message로 이루어져 있다. )
| MessageSet => FirstOffset => int64 Length => int32 PartitionLeaderEpoch => int32 /* Added for KIP-101 */ Magic => int8 /* bump up to “2” */ CRC => int32 /* CRC32C which covers everything from Attributes on */ Attributes => int16 LastOffsetDelta => int32 {NEW} FirstTimestamp => int64 {NEW} MaxTimestamp => int64 {NEW} PID => int64 {NEW} ProducerEpoch => int16 {NEW} FirstSequence => int32 {NEW} Messages => [Message] FetchResponse => ThrottleTime [TopicName [Partition ErrorCode HighwaterMarkOffset AbortedTransactions MessageSetSize MessageSet]] ThrottleTime => int32 TopicName => string Partition => int32 ErrorCode => int16 HighwaterMarkOffset => int64 AbortedTransactions => [PID FirstOffset] PID => int64 FirstOffset => int64 MessageSetSize => int32 |
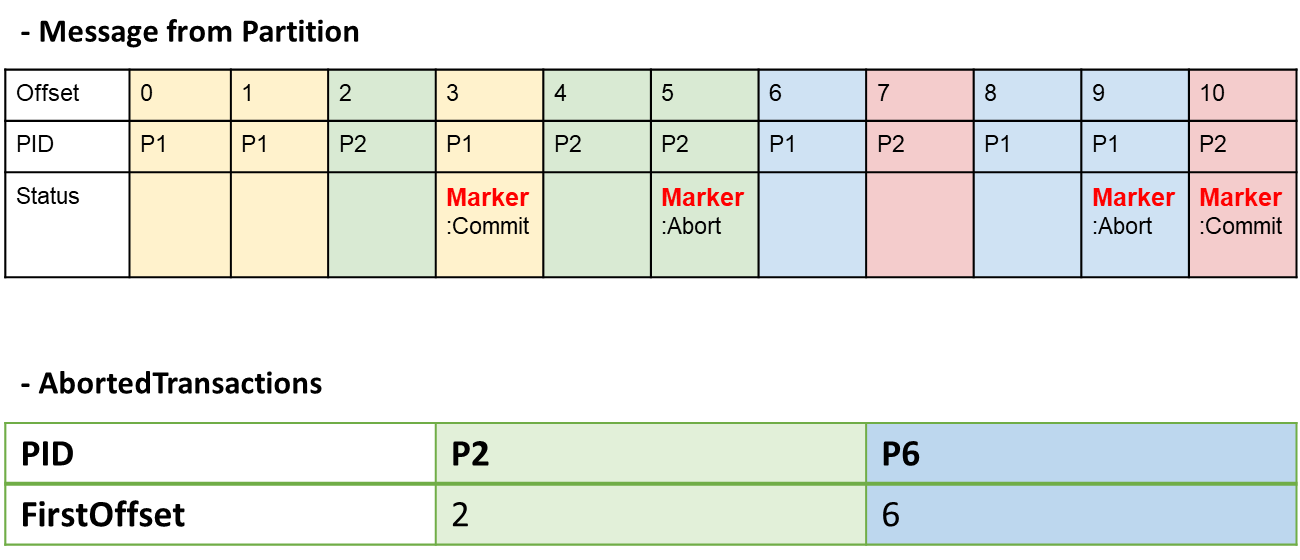
AbortedTransactions은 FetchRequest가 READ_COMMITTED일 경우 Transaction Log에서 읽어오는 Array이다( READ_UNCOMMITTED 이면 null 이다. ). AbortedTransactions는 각 Aborted Transaction들의 First Offset값이 담겨 있다. 이 First Offset과 Marker를 이용하면 해당 Message가 Aborted 된 Transaction의 메시지인지 정상적인 메시지인지 Consumer에서 알 수 있다.
아래 그림에서 처럼 Consumer가 Message를 받았을 경우를 생각해 보자. AbortedTransaction은 Aborted된 Transaction들이 FirstOffset 순서대로 정렬되어 저장되어 있다. 따라서 Consumer는 메시지를 읽다가 AbortedTransaction의 PID=P2, FirstOffset=2 데이터를 확인하고 PID=P2인 메시지는 Abort Marker를 만날때 까지 모두 Drop한다.
댓글