* 이글의 내용 및 그림들의 많은 부분을 아래 자료들로 부터 참고해 왔습니다.
- Computer Architecture: A Quantitative Approach ( 6th edition )
- Prof. Dr. Ben H. Juurlink youtube ( https://www.youtube.com/@prof.dr.benh.juurlink5459/videos )
Instruction-Level Parallelism: Concepts and Challenges
What is Instruction Level Parallelism?
아래 loop를 봐보자. 비록 x[i] = x[i] + y[i]; 부분에서는 병렬적으로 실행할 부분이 적지만, 각 Iteration 1회는 서로 의존적이지 않으므로 병렬적으로 실행될 수 있다( overlap 될 수 있다 ). 이렇게 순차적으로 실행해야 할 명령어를 분석해 병렬적으로 실행할 수 있는지 분석하고, 그리고 그럴 수 있다면 병렬적 실행을 적용하는 문제를 ILP ( Instruction Level Parallelism ) 이라하며, 명령어들을 임의의 순서로 실행을 하는 Out of Order Execution 또한 ILP에 포함된다.
* 여기서 본 loop 예제처럼 루프에 ILP를 적용하는 문제를 Loop Level Parallelism 이라 한다.
| for (i=0; i<=999; i=i+1) x[i] = x[i] + y[i]; |
Data Dependencies and Hazards
Instruction들이 병렬적으로 실행될 수 있는지 판단하려면 각 명령어들 사이에 의존성이 없는지 확인하면 된다. 의존성은 data dependencies, name dependences, control dependencies 3가지가 있다. 만약 Instruction들 그 어떤 의존성도 없다면 서로 “병렬”이라고 하며, 서로 “병렬"인 Instruction은 한 파이프라인에서 동시에 실행될 수 있다( “동시”에 라는 표현이 어색할 수 있는데, 한 파이프라인에서 서로 임의의 순서로 실행될 수 있다는 의미로 받아 들이면 된다. )
Data Dependencies
다음 조건이 만족한다면 Instruction i, j는 서로 data-dependent 하다 라고 말한다.
- Instruction i 가 결과가 instruction j에 의해 사용될 수 있다( 조건 분기에 따라 안될 수도 있지만, 어쨋든 될 가능성이 있다면 data-dependent 하다. )
- j가 k에 data-dependent 하고, k가 i에 data-dependant 하면, j는 i에 data-dependent 하다. 즉 data dependencies는 이행적이다( transitive 하다 ).
예를들어 아래 1, 2, 3 은 data-dependent하며 ( 2→1, 3→2, 그리고 loop로 인해 1→3 ) 4, 5 역시 data-dependent 하다(5 → 4). data-dependent한 instruction들은 서로 동시에 실행할 수 없으며 순차적으로 실행해야 한다.
- e.g-1
| Loop: 1. fld f0,0(x1) //f0=array element 2. fadd.d f4,f0,f2 //add scalar in f2 3. fsd f4,0(x1) //store result 4. addi x1,x1,8 //decrement pointer 8 bytes 5. bne x1,x2,Loop //branch if x1 != x2 |
data value가 단순히 register에서 register로 이동되면 data-depenency를 발견하기 쉽지만, memory가 관련되면 굉장히 복잡해진다. 예를들어 RISC-V의 메모리 참조코드 100(x4) 와 20(x6) 가 다른 메모리를 참조하게 생겼지만 사실은 동일한 메모리를 참조할수도 있기때문이다.
Name Dependencies
동일한 레지스터 혹은 메모리 위치를 사용하지만(앞으로 이것들을 name 이라고 하자), data flow자체는 없을 땐 name dependency가 있다고 한다. data flow는 없는데 왜 dependency인가? 라고 의아해 할 수 있다. 이때 reordering을 생각해보면 되는데, register를 점유하고 사용중인 instruction들 그 중간 사이에 불쑥 동일한 register를 사용하는 instruction을 집어넣을 수는 없다. 따라서 reordering을 행할 때 register의 점유 때문에 pipeline 최적화를 할 수 없어 이 또한 dependency가 된다.
Instruction i 와 프로그램 순서로 그 뒤에 오는 Instruction j가 존재할 때, name dependency에는 다음과 같은 2가지가 존재한다.
- 1. antidependence
i name에 read를 한 이후 j 가 write를 하는 경우이다. 위의 e.g-1 에서 fsd와 addi에는 x1에 대해 antidependence가 존재한다.
- 2. output dependence
i 와 j 둘 다 name에 write를 하는 경우이다. 이 경우는 instruction ordering을 할 때 마지막에 j가 write한 value가 name에 최종적으로 반영되게 유의해야 한다.
사실 name dependency는 실질적인 data flow는 없기에, data dependency처럼 진정한 의존성은 아니다. 따라서 만약 i 와 j 가 사용하는 name( 즉 레지스터, 혹은 메모리 )을 마치 서로 다른 레지스터 혹은 메모리를 사용하는 것 처럼 다른 이름들로 수정(혹은 다른 레지스터로 재배치)하면, 두 instruction들을 동시에 실행시키거나 임의로 reorder 시켜도 문제가 없다. 이때 다른 이름으로 바꾸는 과정을 register renaming 이라 한다.
* register renaming 은 CPU에서도 사용되는 기술이지만 Compiler에서도 사용된다.
ILP에서의 Data Hazard
Control Dependency를 살펴보기 전에, data dependency와 name dependency 로 인한 data hazard를 먼저 살펴보자.
어떤 동일한 데이터 source(레지스터 혹은 메모리)를 사용하는 Instruction i 와 프로그램 순서로 그 뒤에 오는 Instruction j가 존재할 때, 다음과 같은 data hazard가 존재한다.
- RAW (Read After Write) hazard
source에 i 가 write하기 전에, ILP로 인해 j가 먼저 read를 할 수 있다. RAW의 경우는 WAW, WAR와는 다르게 true data dependency이다. i 출력하는 데이터 그 자체에 j가 의존적이다. tomasulo 알고리즘 파트에서 살펴보겠지만, RAW가 존재할 때는 i가 write하는 데이터를 j가 똑바로 읽을 수 있게 프로그램순서를 보존해야한다.
- WAW (Write After Write) hazard
ILP로 인해 i 가 write 하기 전에 먼저 j가 source에 write를 해버릴 수 있다. 이는 사실 i, j에 output dependence 가 존재할 때 발생할 수 있는 hazard이다. tomasulo 알고리즘 파트에서 살펴보겠지만 RAW와는 다르게 true data dependency는 아니기에, renaming을 통해 WAW를 해결할 수 있다.
- WAR (Write After Read) hazard
ILP로 인해 i 가 read를 하기 전에 먼저 j가 write를 해버릴 수 있다. 이는 사실 i, j에 antidependence가 존재할 때 발생할 수 있는 hazard이다. tomasulo 알고리즘 파트에서 살펴보겠지만 RAW와는 다르게 true data dependency는 아니기에, renaming을 통해 WAR를 해결할 수 있다.
Control Dependencies
어떤 Instruction i의 실제 실행 순서가 ( runtime에서의 실행 순서가) 분기 instruction j에 의해 결정된다면 i는 j에 control-dependency가 있다고 한다. 예를들어 아래 e.g-2에서 S1은 p1에 control-dependent하다.
- e.g-2
| if p1 { S1; }; if p2 { S2; } |
단순하게 생각했을 땐 Instruction reordering을 진행할 때 control-dependency과 관련해 다음과 같은 제약을 걸 수 있다.
- 어떤 분기문에 control-dependent한 Instruction은 분기문에 의존적이지 않은 블록으로 옮길 수 없다.
- 어떤 분기문에 control-dependent하지 않은 Instruction은 분기문에 의존적인 블록으로 이동시킬 수 없다.
하지만 control-dependency를 어기면서 ( 분기문을 무시하고 ) 어떤 Instruction을 실행한다 하더라도, 실제 분기에 상관없이 프로그램에 아무런 영향을 주지 않는 명령어라면 ( 아주 간단한 예로 nop instruction ) 사실 control-dependency를 무시하고 reordering(혹은 동시실행)을 해도 문제없다. 다만 현대 CPU는 speculative execution이 있기 때문에, 이럴 땐 보통 이런 CPU들은 단순히 분기가 발생하지 않는다고 가정하고 speculative execution을 실행한다.
다만 data-flow가 영향을 받거나 exception을 낼 가능성이 있는 Instruction이 분기문에 의존적이라면 ( 즉 프로그램에 영향을 주는 명령어들이라면 ), 동시 실행 및 reordering에 주의가 필요하다. e.g-3에서 ld instruction은 분기문을 무시하면 memory segmentation fault가 날 수 있고, e.g-4의 or instruction은 분기문을 무시하면 x1의 값이 달라져서 x7에 저장되는 결과값이 달라질 수 있다. 이런 case들을 data-dependency 만 고려해서 동시실행 및 reordering을 진행하면 프로그램에 영향을 준다. data-flow 및 exception이 control-dependency가 있는 경우를 해결하기 위해 HW Speculation 기술을 이용한다.
- e.g-3
| add x2,x3,x4 beq x2,x0,L1 ld x1,0(x2) L1: |
- e.g-4
| add x1,x2,x3 beq x4,x0,L sub x1,x5,x6 L: ... or x7,x1,x8 |
Overcoming Data Hazards With Dynamic Scheduling
Dynamic Scheduling: The Idea
dynamically scheduling은 2가지를 보장해야 한다.
- dynamically scheduling을 활용한 OOO Execution(Out-Of-Order Execution) 을 위해서는 dependency를 분석해 data-hazard를 일으키지 않아야 한다.
- 정확한 프로그램순서로 실행했을 때와 동일하게 exception 이 발생 혹은 발생하지 않게 해주는걸 정확한 exception ( precise exception) 이라 한다. dynamically scheduling 에선 precise exception을 보장해야 한다. precise exception은 speculation을 이용해 처리하며, 이는 3.6 Hardware-Based Speculation 에서 알아 살펴보도록 한다.
기본적으로 OOO Execution을 위해서는 Standard 5단계 파이프라인 모델의 ID ( Instruction Decode ) 단계를, 다시 2단계로 분할해야 한다.
1. Issue : instruction을 decode하고, structural hazard가 있는지 확인한다.
2. Read Operand : data hazard가 없을 때 까지는 멈췄다가, data hazard가 해소되면 operand를 읽는다.
따라서 다음과 같은 순서가 된다 :
Instruction Fetch - Issue - Read Operand - Execute - Memory Access - WriteBack
이때 IF 단계는 Issue보다 먼저 실행하면서 IR(Instruction Register)에 Instruction을 쓰거나, Pending Instruction Queue에 집어넣는다.
OOO Execution의 장점을 활용하기 위해선 여러 Instruction을 동시에 Execute를 실행할 수 있어야 한다. 따라서 지금부터는 프로세서에 Functional Unit(예를들어 정수 연산을 위한 ALU, 부동 소수계산을 위한 FPU 등등)이 여러개가 중복해서 존재한다고 가정한다.
dynamically scheduled 파이프라인에서는 모든 instruction들은 issue 단계까지는 프로그램 순서 지나가지만, read operand 단계에서는 멈춰있거나 by-passing해서 Execution 단계에는 out-of-order 순서로 도달한다.
data dependency라 없을 땐 scoreboarding이라는 간단한 기법을 적용할 수 있지만, 여기선 무시하고 그냥 tomasulo 알고리즘을 다루도록 한다.
기본적인 tomasulo 알고리즘은 renaming으로 antidependence 와 output dependence를 해결한다. tomasulo 알고리즘을 확장하면 branch prediction을 활용해 speculative execution및 prediction 실패시의 복구를 수행할 수 있다.
Dynamic Scheduling Using Tomasulo’s Approach
tomasulo알고리즘은 Dynamic Scheduling에서의 data hazard를 아래와 같이 해결한다.
- RAW
오퍼랜드가 준비될 때 까지 멈춘다.
- WAR, WAW
register renaming 을 통해 해결한다. 예를들어 아래 RISC 코드를 보자.
| fdiv.d f0,f2,f4 fadd.d f6,f0,f8 fsd f6,0(x1) fsub.d f8,f10,f14 fmul.d f6,f10,f8 |
코드를 살펴보면 총 3개의 antidependence ( WAR ) 및 output dependence( WAW )이 존재함을 알 수 있다.
- WAR : f8에 대한 fsub.d의 write after fadd.d의 read
- WAR : f6에 대한 fmul.d의 write after fsd의 read
- WAW : f6에 대한 fadd.d의 write after fmul.d의 write
물론 true data dependency ( RAW ) 도 존재한다.
- RAW : f0에 대한 fadd.d의 read after fdiv.d의 write
- RAW : f8에 대한 fmul.d의 read after fsub.d의 write
- RAW : f6에 대한 fsd의 read after fadd.d의 write
이를 임시적인 register S, T를 이용해 아래와 같이 renaming을 진행하면 RAW를 제외한 WAR, WAW는 해결할 수 있다. 이때 이 코드 이후에 f8에 대한 read는 반드시 T로 replace 되어야 할 것이다(중간에 추가적인 f8에 대한 write가 없다면 ).
| fdiv.d f0,f2,f4 fadd.d S,f0,f8 fsd S,0(x1) fsub.d T,f10,f14 fmul.d f6,f10,T |
Dynamic Scheduling Using Tomasulo's Algorithm
Key Components
아래 예제를 보자. fadd.d가 fdiv.d에 의한 data dependency가 존재하므로, stall하게 된다. in-order execution이라면 fsub.d는 의존성이 없음에도 불구하고 같이 멈춰버릴 것이다.
| fdiv.d f0,f2,f4 fadd.d f10,f0,f8 fsub.d f12,f8,f14 |
- Reservation Station ( RS )
따라서 위 예제에서 out of order execution를 위해 fsub.d가 실행되려면, operand가 준비되길 기다리고 있는 fadd.d는 어딘가에 “buffered” 되어야 한다. 이렇게 대기중인 instruction을 저장하는 buffer를 Reservation Station( 줄여서 RS ) 이라 하며, 토마술로 알고리즘에는 여러개의 Reservation Station이 존재한다.
- Common Data Bus ( CDB )
이때 만약 fadd.d가 기다리고 있던 데이터 ( f0 )값이 Functional Unit에 의해 드디어 산출되었다면, FU는 이를 Reservation Station에게 알려줘야 한다. 따라서 FU는 데이터 산출이 끝날 때 마다 특정한 Bus를 이용해 모든 Reservation Station들에게 알려주게 되는데, 이 Bus를 Common Data Bus ( CDB ) 라고 한다.
Tomasulo Pipeline Phase
토마술로 파이프라인에서는 각 Phase들이 여러 cycle을 차지할 수 있다.
IF
Instruction을 pending instruction FIFO Queue에 집어넣는다. 이제부터 이 Queue를 instr queue라 하자.

Issue
instr queue 의 head 있는 Instruction을 하나 “가져"온다( Pop이 아니라 Get이므로, 아직 제거하는것은 아니다). 이때 “matching” 되는 free상태인 RS가 존재한다면, 해당 RS로 Issue한다. 하지만 matching되는 free 상태인 RS가 없다면, 어쩔수 없이 프로세서는 stall 해야한다( 즉 structural hazard로 인한 stall ).
이때 matching 되는 이라는 뜻은, 사실 각 RS들은 특정 연산에만 사용될 수 있다.예를들어 아래 그림에는 5개의 RS들이 있는데, 3개의 RS Add1, Add2, Add3 는 Add 연산에만 사용될 수 있고, 2개의 RS Mul1, Mul2는 Mul 연산에만 사용될 수 있다.

matching 되는 free상태인 RS가 존재해서 Instruction을 집어 넣을 땐, 다음과 같이 operand 정보를 써 넣어야 한다.
- 이때 만약 instruction의 operand value가 register에 존재한다면, instruction을 RS에 집어 넣을 때 해당 값을 같이 RS에 써 넣는다
- 그게 아니면 operand value는 아직 어느 RS에서 생산하고 있는 중이다. 따라서 instruction을 집어 넣을 때 해당 RS의 identifier(예를들면 위 그림에서 Mul1 과 같은 )를 써 넣는다.
Read Operand
Instruction의 Issue단계에서 operand value가 모두 register에 존재했다면, RS에는 필요한 operand value가 모두 완비된 상태이고, 따라서 곧바로 Execute를 할 수 있는 상태이다.
하지만 그게 아니라면 RS는 operand value를 채워넣기 위해 CDB를 통해 출력되는 값을 기다려야 한다.
Execute
모든 operand가 준비된 RS가 존재한다면, free 상태인 FU로 보낸다.
나머지 RS들은 아직 operand가 준비되지 않은 (즉 RAW hazard가 있는 ) instruction이다. 이런 RS들은 Write Result 단계에서 FU들이 CDB에 출력한 값들을 보고 operand를 채워넣어야 한다.
Memory Access
현재는 register 접근만 고려하므로, Memory Access phase가 활용되는 내용은 다음 장에서 알아보자.
Write Result (+ Read Operand )
FU들은 Execute가 완료되면 이를 CDB를 통해 출력하는데, 출력값에는 이 명령을 실행한 RS의 identifier도 포함된다. 따라서 CDB를 통해 Register File(혹은 그냥 Register) 그리고 해당 데이터를 기다리고 있던 RS의 operand에 값을 써 넣을 수 있다.
예를들어 아래에서 FP adder에서 Add2가 실행시킨 출력값(2.0)이 계산되어져 CDB에 broadcast 되어지고 있다. 따라서 Mul2와 FP Register의 F1에 해당값을 써 넣으면 된다.
- 1. FP adder 결과가 CDB에 broadcasting된다. - 2. RS와 Register File은 CDB를 분석해 결과값을 채워넣는다.  |
Components Structure
Reservation Station Structure
Reservation Station은 7개의 필드가 있다.
- op
operation의 종류
- RS1, RS2 (혹은 Qj, Qk 로 표기 )
operation에 필요한(즉 dependency가 있는) operand value를 생산중인 RS의 identifier 값이다. 만약 이미 데이터가 준비되었다면 0을 써 넣는다. 예를들어 아래에서 그림에서 Val2는 이미 준비되었기에, RS2는 0이다.
- Val1, Val2 (혹은 Vj, Vk 로 표기 )
기다리고 있던 dependency value가 CDB에 의해 출력되면 Write되는 필드이다. RS는 CDB를 읽다가 기다리던 RS identifier 가 발견되면, 출력값을 써 넣는다.
- Imm/Addr (혹은 그냥 A로 표기)
Instruction의 Imm 혹은 Addr 값이다. 일반적으로 Imm일 경우는 하드코딩 이므로, Issue단계에서 같이 채워지지만, Addr인 경우는 실행 도중에 계산되어 질 수 있다( 예를들어 STORE.D F1, [R1] 같은 경우 R1 레지스터 값이 실행 도중 결정되므로 ).
- busy
RS가 available 한가를 나타낸다.

Register File
토마술로 알고리즘을 적용한 시스템의 레지스터(레지스터 파일)에는 Value를 넣는 field 뿐만 아니라, RS identifier를 뜻하는 RS 필드 또한 존재한다. 레지스터에 있는 RS 필드의 RS identifier값은 해당 RS identifier가 그 레지스터의 값(Value field)를 생산중임을 나타낸다. 따라서 특정 Instruction이 특정 레지스터를 사용할 때, 해당 레지스터의 RS field에 RS identifier값이 존재한다면 아직 value를 생산중이므로 기다려야 한다. 예를들어 아래 그림에서 F1 레지스터 값은 Mul1 RS가 생산중이다.

Dynamic Scheduling: Examples and the Algorithm
Dynamic Scheduling Using Tomasulo's Algorithm Example
다음과 같은 기계어를 Tomasulo로 OOO Execution 하는 과정을 예제로 살펴볼 것이다.
* youtube 예제라서 기계어 형태가 조금 다르다( fmul.d → MUL.D )
| MUL.D F0,F1,F2 ADD.D F3,F0,F2 SUB.D F0,F1,F2 |
이때 아래그림처럼 F0 ~ F3 register들은 각각 0.0 ~ 3.0 인 상태라고 하자. 그리고 instruction들은 fetch unit에 의해 instr queue에 순서대로 들어가 있는 상태이다.
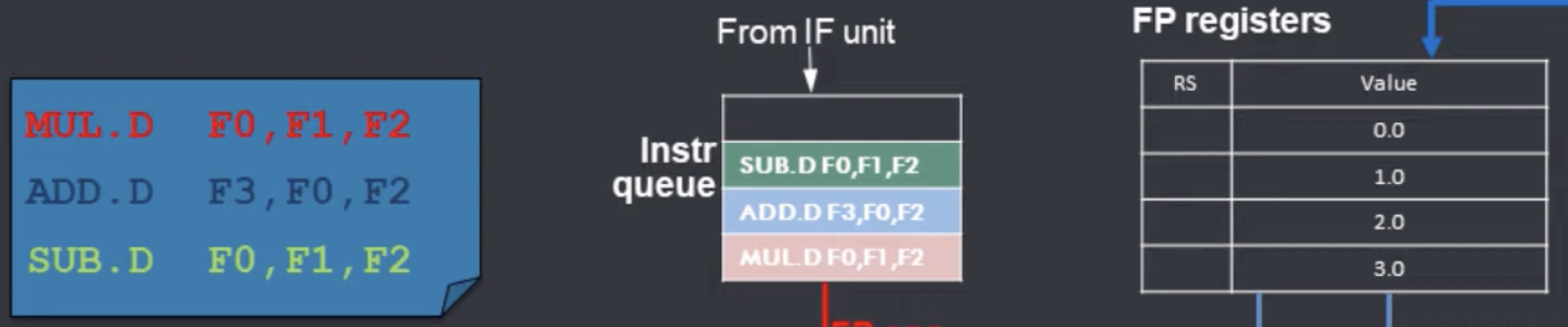
이제 차근차근 instruction들을 issue 하는 과정을 봐보자.
- 1. Issue MUL.D
Mul1 RS가 available 하므로 Mul1 RS 로issue 된다. 이때 MUL.D 가 필요로 하는 F1, F2가 “생산중"이 아니므로, 레지스터 값을 그대로 가져다가 RS의 Vj, Vk 필드에 같이 써넣으면 된다. Issue가 될 때에는 출력 레지스터(MUL.D 의 경우에는 F0)의 RS field에도 자신이 “생산중" 임을 표시해줘야 한다.
Mul1 RS 는 Issue하는 과정에서 operand value가 모두 채워졌으므로, Issue를 하는 즉시 “Executable” 한 상태가 된다.
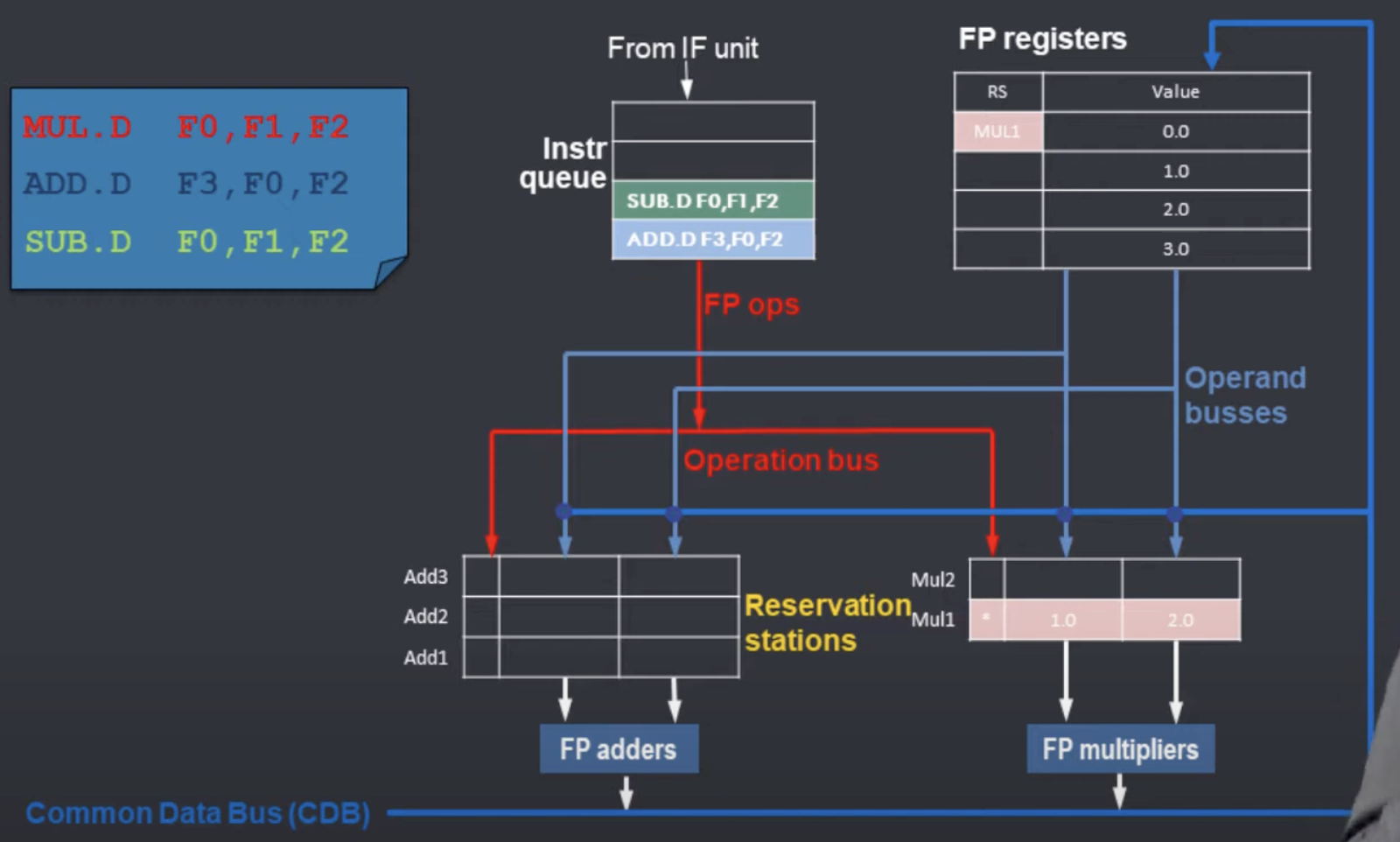
- 2. Issue ADD.D
Add1 RS가 available 하므로 Add1 RS 로 issue 된다. 이때 ADD.D 가 필요로 하는 F2 는 생산중이 아니므로 그대로 Vk 필드에 써 넣으면 되지만 F0 은 Mul1에 의해 “생산중" 이므로 RS1 필드에 dependency가 있는 RS ( Mul1 RS )의 identifier를 써 넣는다. 여기서 tomasulo가 true data dependence ( RAW hazard )를 보존하는 방법을 보여주는데, 의존성이 있는 RS의 출력( Mul1 의 출력)을 기다리는 것으로, data dependency를 보존함을 알 수 있다.
마찬가지로 Issue가 될 때에는 출력 레지스터(ADD.D 의 경우에는 F3)의 RS field에 자신이 “생산중" 임을 표시해줘야 한다.

- 3. Issue SUB.D
Add2 RS가 available 하므로 Add2 RS 로 issue 된다. 이때 SUB.D 가 필요로 하는 F1, F2가 “생산중"이 아니므로, 레지스터 값을 그대로 가져다가 RS의 Vj, Vk 필드에 같이 써넣으면 된다.
SUB.D가 Issue가 될 때에는 출력 레지스터 F0의 RS field에 자신이 “생산중" 임을 표시해줘야 하는데, 이때 이미 RS field가 채워져있어도 overwrite를 한다. 이때 output dependence 와 antidependence 가 해결되는 과정을 살펴볼 수 있다.
- output dependence : SUB.D 는 F0에 대한 MUL.D 와의 output dependence (WAW hazard) 가 있었다. 하지만 레지스터의 RS field를 Issue를 in-order로 진행하면서 overwrite하기에, 레지스터에 F0 에는 나중에 Issue된 SUB.D의 출력물에 쓰여져 WAW hazard 를 해소한다. 또한 F0은 Mul1 이라는 이름으로 renaming 되었기에, ADD.D 는 Add1 RS에서 Mul1 라는 이름을 이용해 필요한 F0 값을 읽을 수 있으므로 output dependence는 사라졌다.
- antidependence : SUB.D 는 F0 에 대한 ADD.D 와의 antidependence ( WAR hazard ) 가 있었다. ADD.D 에서의 F0은 Mul1 라는 이름으로 renaming 되었으며, SUB.D 에서의 F0 은 Add2라는 renaming 되었기에 antidependence는 사라졌다.
Mul1 RS와 마찬가지로 Add2 RS 는 Issue하는 과정에서 operand value가 모두 채워졌으므로, Issue를 하는 즉시 “Executable” 한 상태가 된다.

토마술로의 문제점
토마술로는 정확한 exception 을 보장하지 않는다.
예를들어 뒤에 있던 명령어가 먼저 실행이 되어 Register File에 있는 F0 레지스터를 Write한 상황에서, 앞에 있는 명령어를 뒤늦게 실행하다 exception이 발생한 상황을 가정해 보자. F0값은 앞에 있던 명령어에 의해 변경되어선 안되지만, exception이 발생한 상황에선 이미 변경되어 버렸다.
이런 문제점에 대한 해결책은 Instruction-Level Parallelism : Hardware Based Speculation for OoO Execution
(https://zbvs.tistory.com/37)글에서 다루도록 하자.
Extending Tomasulo with Memory Accesses
주소를 모르는 경우
지금까지는 레지스터만 다뤘지만, 메모리에 대한 Memory Load/Store 역시 동일하게 data-hazard들을 가진다. 하지만 주소가 계산되기 전 까지는 Load, Store 명령어들이 같은 주소를 가리키는지 알 수 없고, 따라서 어떤 hazard가 있는지도 판단할 수 없다.

그렇다면 이때 Memory Load/Store 명령어 들은 Instruction Queue에 대기하면서, 전체 Processor에 stall 해야할까? 이를 회피하는 방법이 2가지 있다.
- HW Speculation을 이용한다.
HW Speculation을 이용해 commit 되기 전에는 상태를 되돌릴 수 있다. 또한 Address를 반드시 정확히 계산할 필요는 없이, 대충 예상해서 같은지 아닌지만 예상하면 된다.
즉 prediction 기술을 이용해 대충 “같은주소인가 다른주소인가" 만 예상해서 speculative하게 실행하고, Address 계산이 끝나고 봤더니 틀렸다면 roll-back한다.
- Store, Load말고 다른 명령어를 먼저 실행한다.
어떤 한 Store 명령어가 주소를 몰라 막혔다고 하자. 이때 Store/Load가 아닌 다른 명령어들은 먼저 실행할 수 있다. 따라서 Store/Load는 또다른 대기큐( Store Buffer / Load Buffer가 아니다. )로 빼내고, 그 외 명령어를 먼저 실행한다.
주소를 아는 경우
전체 프로세서 stall 없이 Memory Load/Store의 아는 상태에서 Issue 할 수 있다. 일단은 지금은 Memory Load/Store
Issue가 되는 단계에서 주소를 이미 알고있다고 가정하자 보자.
주소를 아는 경우는 주소를 비교하여 data-hazard가 존재하는지 판단 가능하다.

data-hazard 검사
Memory Load/Store 들은 Issue가 되려면 data-hazard가 없어야 Issue가 될 수 있다. 그렇지 않으면 전체 Issue는 stall 된다( 실제 현대 프로세서는 전체 Issue가 stall 되지 않게 대기 Queue등이 존재하겠지만 일단은 그렇게 생각하자 ).
Issue가 된 이후에는 각각 Load Buffer/Store Buffer에 저장된다. Load Buffer/Store Buffer 는 Memory Load/Store 명령어 전용 Reservation Station이라고 생각해도 무방하다. Load Buffer/Store Buffer 는 모두 Identifier를 가지며(예를들어 아래 그림에서 Sb1, Sb2, Sb3, Lb1, Lb2, Lb3), Load 명령어의 경우는 완료시 다른 일반 명령어와 동일하게 CDB를 통해 broadcasting된다( Store는 Broadcasting 필요가 없다).

Issue를 할 때 data-hazard를 검사하는 방법은 다음과 같다.
- Load:
Load의 경우는 RAW hazard가 있는지 검사해야 한다. 예를들어 아래 그림에서 L.D F1, 1000(R0) 명령어를 Issue할 때, Store Buffer에 있는 Store 명령 중 동일한 동일한 주소를 가진 Store 명령어가 있다면 Load Buffer로 보내져서는 안되고 멈춰야 한다.
- Store:
Store 는 WAR, WAR 두 가지의 hazard를 검사해야 한다. 이 것 외에 나머지 과정은 Load와 동일하다.

Load 명령어 CDB broadcasting
Load 명령어는 완료시 CDB에 broadcasting이 된다. RS(Reservation Station)들 중 아래와 같이 LoadBuffer들의 출력을 기다리는 RS가 있다면(예를들어 아래그림에서 RS1 field 필드를 보면 Lb2를 기다리고 있다), CDB의 값을 체크하고 identifier가 일치한다면 operand(예를들어 아래그림에서 Val1 field)값을 채워넣을 수 있을 것이다.

'Compiler & Computer Architecture' 카테고리의 다른 글
| Memory Consistency Model (0) | 2023.10.24 |
|---|---|
| Cache coherency protocols (3) | 2023.10.24 |
| Instruction-Level Parallelism : Hardware Based Speculation for Out-of-Order Execution (0) | 2023.10.24 |
| Hypervisor ( x64 ) (0) | 2022.01.16 |
| CPU Cache 사상과 회로 구성 (0) | 2021.12.04 |




댓글