* 이글의 내용 및 그림들의 많은 부분을 아래 자료들로 부터 참고해 왔습니다.
- Computer Architecture: A Quantitative Approach ( 6th edition )
- Prof. Dr. Ben H. Juurlink youtube ( https://www.youtube.com/@prof.dr.benh.juurlink5459/videos )
Introduction to Multiprocessor System Memory Architectures
여러프로세서와 캐시 및 메모리를 구성하는 방법은 크게 Centralized Shared-Memory Architectures, Distributed Shared-Memory ( DSM ) 로 나눌 수 있다.
Centralized Shared-Memory Architectures
모든 프로세서가 전역 버스를 통해 공유된 메인 메모리에 접근하는 구조이다. 메인 메모리 중간에는 L1, L2 와 같은 private cash와 L3와 같은 shared cache가 있을 수 있다.
일반적으로 Centralized Shared-Memory 아키텍처는 “모든 메모리”에 access 시간이 동일하기에 UMA ( Uniform Memory Access time ) 아키텍처라고 할 수 있다.

Symmetric Multiprocessor (SMP)
Centralized Shared-Memory 아키텍처에서, 만약 모든 프로세서가 모두 “동등한 권한 과 역할" 을 가진다면 해당 시스템을 Symmetric Multiprocessor (SMP) 라고 한다. Centralized Shared-Memory 라 하더라도, 특정 프로세서의 역할이 다르거나 권한이 서로 다르다면 SMP가 아니다.
* Centralized Shared-Memory에서 만약 각 프로세서마다 역할이나 권한이 다르다면 AMP ( Asymmetric Multiprocessing ) 라고 부른다.
Distributed Shared-Memory ( DSM )
각 프로세서마다 자신의 local memory를 가지며, 따라서 다른 프로세서의 메모리에는 더 느린 버스(혹은 네트워크)를 통해 연결되어 있어 시⬝공간적으로 더 멀리 떨어진 구조이다. 각 메모리마다 access 시간이 불균등하기에 NUMA ( Non-Uniform Memory Access time ) 아키텍처라고 할 수 있다.

Centralized Shared-Memory Architectures
What Is Multiprocessor Cache Coherence?
coherent memory system
모든 프로세서가 어떤 시점에서라도 특정 메모리 주소에 대한 일관된(동일한) 상태를 관찰하는 시스템을 coherent memory system 이라 한다. coherent memory system은 다음을 보장해야 한다.
- preserve program order
중간에 다른 프로세서가 write를 하지 않는다면, 한 프로세서가 write를 한 이후 다시 read를 하면 자신이 write한 value가 return 되어야 한다.

- coherent memory view
한 프로세서가가 write한 이후, 다른 프로세서는 “충분한 시간이 지난 이후" written 된 value를 읽을 수 있다.

- Write serialization
서로 다른 프로세서들이 write를 했을 때, 해당 write들은 모든 프로세서가 “동일한 순서”로 관찰한다.

Classes of Cache Coherence Protocols
멀티프로세서의 coherent memory system은 Coherence Protocol에 의해 구현된다. Coherence Protocol에는 snooping protocol, Directory based protocol 가 있다.
snooping protocol
각 코어의 cache controller가 write와 같은 event를 버스를 통해 broadcasting하고, 다른 cache controller는 bus를 계속 snooping하다 event를 읽고 대응하는 방식이다. 이때 event에는 어떤 메모리 주소에 해당하는 block인지를 나타내는 정보가 담겨있어야 한다.

snooping protocol 에는 다시 Write Invalidate, Write Update 2 종류가 있다. Write Invalidate 는 write시에 모든 복사본 ( cache 복사본 ) 을 invalidating 시키는 방식이며, Write Update 는 write시에 다른 모든 복사본들도 update 시키는 방식이다. 일반적으로 Write Invalidate 방식이 bus에 broadcast가 적으므로 주로 쓰이는 방식이다.
| Scenario / Metric | Write Invalidate | Write Update |
| Multiple writes to same word: - e.g) Write(addr), Write(addr), Write(addr) ... |
1 invalidation | Multiple write broadcasts |
| Writes to different words in same cache block: - e.g) Write( block1[0x0] ), Write( block1[0x8] ), Write( block1[0x10] ) ... |
1 invalidation | Multiple write broadcasts |
| Delay between writing in 1 core and reading in another | Longer | Shorter |
Directory based protocol
어떤 복사본 ( cache ) 가 존재하는지에 대한 정보를 directory라 불리는 장소에서 관리한다.
Write Invalidate Protocols
상용 멀티프로세서 시스템에서 일반적으로 쓰이는 방식은 Write Invalidate 이므로, 대표적인 Write Invalidate Protocol인 MSI Protocol, MESI Protocol에 대해 알아보자.
MSI Protocol
https://en.wikipedia.org/wiki/MSI_protocol
앞으로 CPU의 cache read/cache write를 다음과 같은 CPU operation으로 정의하자.
| PrRd | 캐시에 대한 CPU Read 동작이다. |
| PrWr | 캐시에 대한 CPU Write 동작이다. |
MSI protocol에서는 다음과 같은 3가지의 Bus Request가 존재한다.
* BusRdx, BusUpgr 와 같은 invalidating request가 동일한 block에 대해 여러 프로세서에서 동시에 발생하면, 일반적인 MS 구현에서는 “빠른 번호 순" 프로세서를 우선으로 구현한다.
| BusRd ( Bus Read ) |
CPU Read( PrRd )를 했더니 Read Miss가 발생했을 때, 다른 cache로 부터 block을 요청하기 위한 request이다. |
| BusRdx ( Bus Read Exclusive) |
CPU Write( PrWr )를 했더니 Write Miss가 발생했을 때, block에 대한 독점적인 권한을 가지기 위한 요청이다. 다른 cache로 부터 block을 요청하고 해당 block을 소유한 모든 cache에게 block을 invalidate를 하도록 요청하는 request이다. |
| BusUpgr | CPU Write( PrWr )를 했더니 Write Hit일 때(block이 존재할 때), block에 대한 독점적인 권한을 가지기 위한 요청이다. 사실상 cache hit인 것 빼고는 BusRdx와 동일하다. |
MSI protocol에서는 block은 다음과 같은 3가지 상태로 존재한다. block의 상태에는 위에서 본 2가지 요인( CPU Operation, Bus Request) 에 의한 Transition 발생할 수 있다.
| invalid | 해당 데이터가 존재하는 block이 “not existing” 혹은 “invalid” 한 상태이다. 따라서 다른 cache나 main memory로 부터 block을 가져와야 한다. |
| shared | cache에 block이 존재하고, 하나 이상의 또다른 cache에도 block이 존재하는 상태이다. cache에 block이 존재하므로 별도의 요청 없이 read를 할 수 있다. |
| modified | block이 오직 자신의 cache에만 존재하는 상태이다. 다른 cache에는 block이 없으므로, 별도의 communication없이 read/write를 할 수 있다. |
- Transition by CPU operation

| invalid | ∗ on PrRd → shared CPU가 cache를 읽었는데 해당 block이 존재하지 않으면 (block 하나를 eviction을 시켜) 새로운 block을 shared 상태로 transition 시킨다. 또한 bus에 BusRd request를 broadcast 한다. ∗ on PrWr → modified CPU가 cache에 write를 했는데 해당 block이 존재하지 않으면 (block 하나를 eviction을 시켜) 새로운 block을 modified 상태로 transition 시킨다. 또한 bus에 BusRdx request를 broadcast 한다. |
| shared | ∗ on PrRd → shared CPU가 cache를 읽었더니 해당 block 존재하고 shared 상태이면 shared 상태로 남게 된다. 이 경우 그 어떤 request도 broadcast하지 않는다. ∗ on PrWr → modified CPU가 cache에 write를 했는데 해당 block이 존재하고 shared 상태이면 그 block을 modified 상태로 transition 시킨다. 또한 bus에 BusUpgr request를 broadcast 한다. |
| modified | ∗ on PrRd/PrWr → modified CPU가 read/write를 했더니 해당 block 존재하고 modified 상태이면 modified 상태로 남게된다. 이 경우 그 어떤 request도 broadcast하지 않는다. |
- Transition by Bus Request

| modified | ∗ on BusRd → shared modified 상태의 block을 가진 상태에서 BusRd request를 받으면 해당 block을 shared 상태로 만들면서 다음을 수행한다. - request를 보낸 cache의 main memory 접근을 중단시키고( main memory로 부터는 old data를 받을 것이므로) 현재 block 데이터를 준다. - main memory에도 현재 block 데이터를 반영한다. ∗ on BusRdx → invalid modified 상태의 block을 가진 상태에서 BusRdx request를 받으면 해당 block은 다른 cpu에 의해 write를 당할것임을 의미하므로 block을 invalidating을 한다. invalidating을 하면서 BusRd를 받았을 때와 동일한 동작을 수행한다( BusRdx request를 보낸 cache 역시 최신 데이터가 필요하므로, 데이터를 보내줘야 한다.). |
| shared | ∗ on BusRd → shared main memory가 request를 날린 cache에게 데이터를 줄 것이기 때문에, shared 상태의 block을 가진 상태에서 BusRd request를 받으면 아무 행동도 취하지 않는다. ∗ on BusRdx/BusUpgr → invalid shared 상태의 block을 가진 상태에서 BusRdx/BusUpgr request를 받으면 해당 block은 다른 cpu에 의해 write를 당할것임을 의미하므로 블록을 invalidating 한다. |
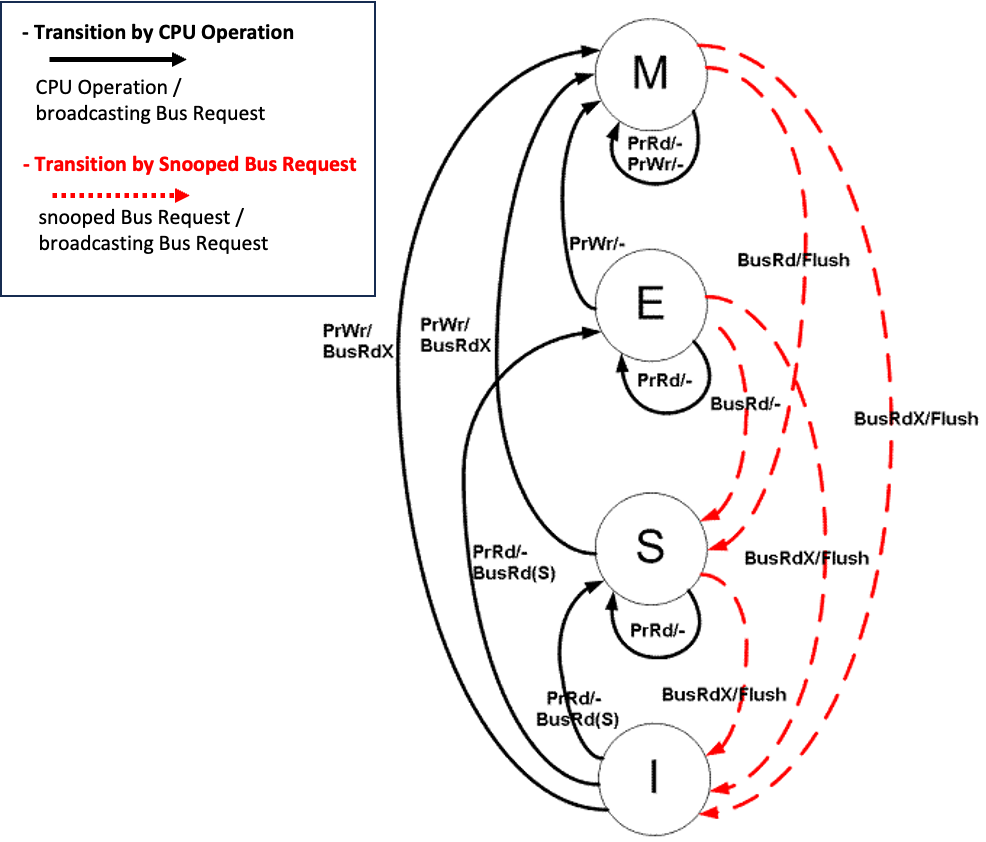
MESI Protocol
https://en.wikipedia.org/wiki/MESI_protocol
MSI Protocol의 문제는 쓸데없는 BusUpgr request가 발생할 수 있다는 점이다. 예를들어 아래 왼쪽처럼 프로세서 P1이 변수 A를 read한 후 write를 했을 때, 블록을 copy를 가진 ( 즉 shared 상태인 ) 캐시가 없음에도 BusUpgr request를 broadcast 하게 된다.

이때문에 MESI Protocol에는 exclusive 상태가 추가되었다.
- 아래 왼쪽 그림은 invalid 상태에서의 transition을 나타낸다. invalid 상태에서 PrRd시 그 어떤 copy도 report 되지 않으면, main memory로 부터 block을 받고 block을 exclusive 로 transition 한다. 이미 다른 cache가 복사본을 가지고 있다면 shared로 transition한다.
- 아래 오른쪽 그림은 exclusive 상태의 transition을 나타낸다(설명은 그림으로 충분하니 생략).

MESI Protocol의 transition을 CPU Operation 에 따른 transition(아래 그림에서 왼쪽 편)과 Bus Request snooping에 의한 transition(아래 그림에서 오른쪽 편)으로 나타내면 아래 그림과 같다.
'Compiler & Computer Architecture' 카테고리의 다른 글
| Memory Consistency Model (0) | 2023.10.24 |
|---|---|
| Instruction-Level Parallelism : Hardware Based Speculation for Out-of-Order Execution (0) | 2023.10.24 |
| Instruction-Level Parallelism : Out-Of-Order Execution (0) | 2023.10.24 |
| Hypervisor ( x64 ) (0) | 2022.01.16 |
| CPU Cache 사상과 회로 구성 (0) | 2021.12.04 |



댓글